日志收集工具
轻量级
轻量级的Agent有:
- Filebeat
- Fluent-bit
优点
- 轻量级
- 零依赖(Fluent-bit编译依赖)
- 插件多
- 多种input
- 多种output
缺点
轻量级的更多的专注采集,信息转换不是很擅长,一般都是由下游的服务(Logstash,Fluent等)来转换。
Filebeat
Beats平台集合了多种单一用途数据采集器。
Beats系列:
- Filebeat
- Metricbeat
- Packetbeat
- Winlogbeat
- Auditbeat
- Heartbeat
- Functionbeat
Filebeat是我们最常用的。
Filebeat是一个开源的文件收集器,也是一款轻量级的日志传输工具。采用go语言开发,重构logstash采集器源码,安装在服务器上作为代理来监视日志目录或特定的日志文件。是elastic家族成员。
Filebeat可以保持每个文件的状态,并且频繁地把文件状态从注册表里更新到磁盘。这里所说的文件状态是用来记录上一次Harvster读取文件时读取到的位置,以保证能把全部的日志数据都读取出来,然后发送给output。
如果在某一时刻,作为output的ElasticSearch或者Logstash变成了不可用,Filebeat将会把最后的文件读取位置保存下来,直到output重新可用的时候,快速地恢复文件数据的读取。在Filebaet运行过程中,每个Prospector的状态信息都会保存在内存里。如果Filebeat出行了重启,完成重启之后,会从注册表文件里恢复重启之前的状态信息,让FIlebeat继续从之前已知的位置开始进行数据读取。 Prospector会为每一个找到的文件保持状态信息。因为文件可以进行重命名或者是更改路径,所以文件名和路径不足以用来识别文件。对于Filebeat来说,都是通过实现存储的唯一标识符来判断文件是否之前已经被采集过。
如果在你的使用场景中,每天会产生大量的新文件,你将会发现Filebeat的注册表文件会变得非常大。这个时候,你可以参考the section called “Registry file is too large?edit,来解决这个问题。
Fluent bit
Fluent bit是一个用c写成的插件式、轻量级、多平台开源日志收集工具。它允许从不同的源收集数据并发送到多个目的地。完全兼容docker和kubernetes生态环境。
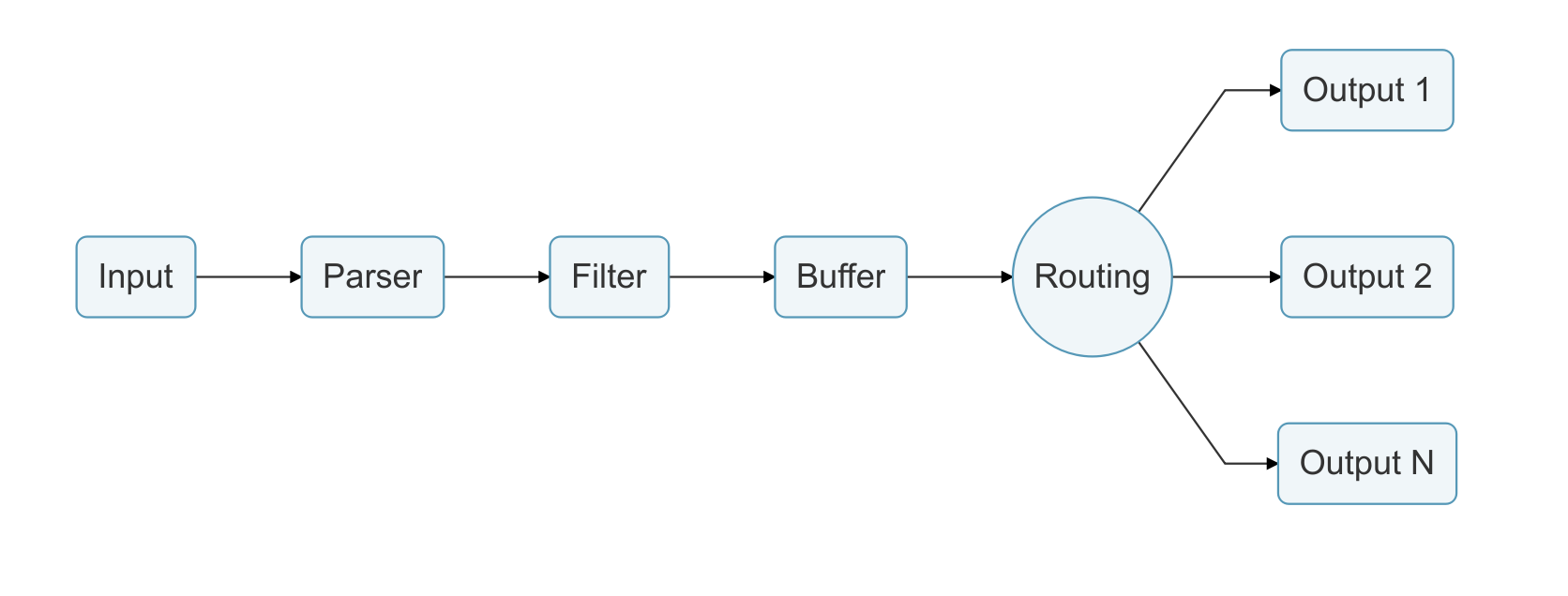
Fluent bit工作流程
重量级
常见的日志收集工具:
- Ingest Node
- Logstash
- Fluentd
- Flume
- Apache Nifi
Fluentd算是资源占用少的了40M左右。
以上的收集工具都可以输入到Kafka
引入Kafka 的优势
- 可以异步处理数据,防止突发流量。
- 解耦,下游服务宕机,不会影响收集。
- 减少下游的资源消耗。
使用哪种收集工具,是否引入Kafka,还要具体需求具体分析,引入是增加复杂度的。
举个例子:请看Ingest Node
Ingest Node
如果你收集的日志量不大,或者丢了一些也能接受,并且指向输入到ES,那么Ingest Node也适合你。

Ingest Node作为Elasticsearch索引文档过程的一部分,仅能使用Elasticsearch支持的方式来输入,如Restful接口等,处理过后的数据也只能索引入Elasicsearch中,而不能输出到其他地方。
Elasticsearch本身并没有提供数据缓冲策略,数据输入端需要自行解决ES拒绝写入请求的情况。而Ingest Node作为ES索引文档的一部分也没有数据缓冲策略。
Ingest Node支持超过20多种processors,这些processors覆盖了Logstash的常用场景。限制是只能在单个数据的上下文执行,另外不能调用外部的系统,如文件,数据库等
Ingest Node通过ES接口创建Pipeline, 并存入Elasticsearch中,无监控和可视化管理界面。
当然需求不满足,你可以看Logstash。
Logstash
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。提供 Web 接口用于查询和统计。是elastic家族成员。
Logstash由Java(Core)+Ruby(Plugin)语言编写。
Logstash 数据处理可以分为三个阶段:
- inputs:产生数据来源,例如文件、syslog、redis 和 beats 此类来源。
- filter:修改过滤数据, 在 Logstash 数据管道中属于中间环节,可以根据条件去对事件进行更改。一些常见的过滤器如下:grok、mutate、drop 和 clone 等。
- outputs:将数据传输到其他地方,一个事件可以传输到多个 outputs,当传输完成后这个事件就结束。Elasticsearch 就是最常见的 outputs。
同时 Logstash 支持编码解码,可以在 inputs 和 outputs 端指定格式。

优点
- 插件多
- 灵活
- 应用场景丰富
缺点
- 性能
- 资源占用高
Fluentd
Fluentd是一个开源的数据收集器,专为处理数据流设计,使用JSON作为数据格式。它采用了插件式的架构,具有高可扩展性高可用性,同时还实现了高可靠的信息转发。Fluentd是云端原生计算基金会(CNCF)的成员项目之一,遵循Apache 2 License协议。 性能敏感的部分用C语言编写,插件部分用Ruby编写,500多种插件。 更轻量级的 Fluent-Bit 对应 Filebeat。
Fluentd有5种类型的插件,分别是:
- Input:完成输入数据的读取,由source部分配置
- Parser:解析插件
- Output:完成输出数据的操作,由match部分配置
- Formatter:消息格式化的插件,属于filter类型
- Buffer:缓存插件,用于缓存数据
Flume
Flume是由cloudera软件公司产出的可分布式日志收集系统,后与2009年被捐赠了apache软件基金会,为hadoop相关组件之一。尤其近几年随着Flume的不断被完善以及升级版本的逐一推出,特别是flume-ng;同时flume内部的各种组件不断丰富,用户在开发的过程中使用的便利性得到很大的改善,现已成为apache top项目之一.
Flume使用JRuby来构建,所以依赖Java运行环境。
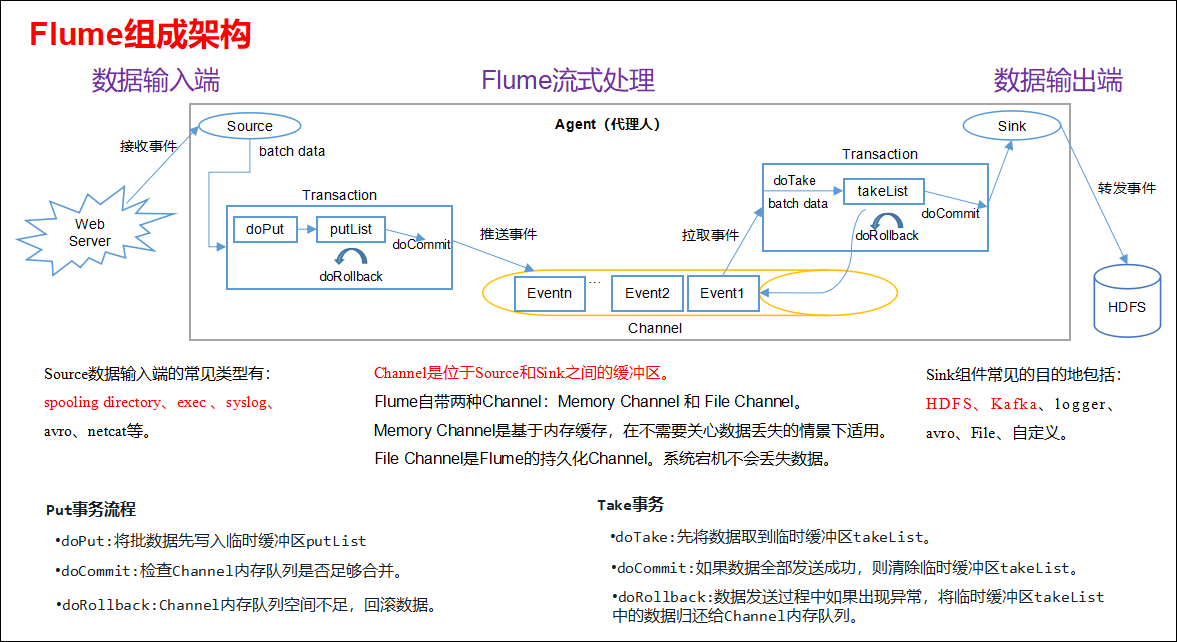
Flume的一些核心概念:
- Client:Client生产数据,运行在一个独立的线程。
- Event: 一个数据单元,消息头和消息体组成。(Events可以是日志记录、 avro 对象等。)
- Flow: Event从源点到达目的点的迁移的抽象。
- Agent: 一个独立的Flume进程,包含组件Source、 Channel、 Sink。(Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。)
- Source: 数据收集组件。(source从Client收集数据,传递给Channel)
- Channel: 中转Event的一个临时存储,保存由Source组件传递过来的Event。(Channel连接 sources 和 sinks ,这个有点像一个队列。)
- Sink: 从Channel中读取并移除Event, 将Event传递到FlowPipeline中的下一个Agent(如果有的话)(Sink从Channel收集数据,运行在一个独立线程。)
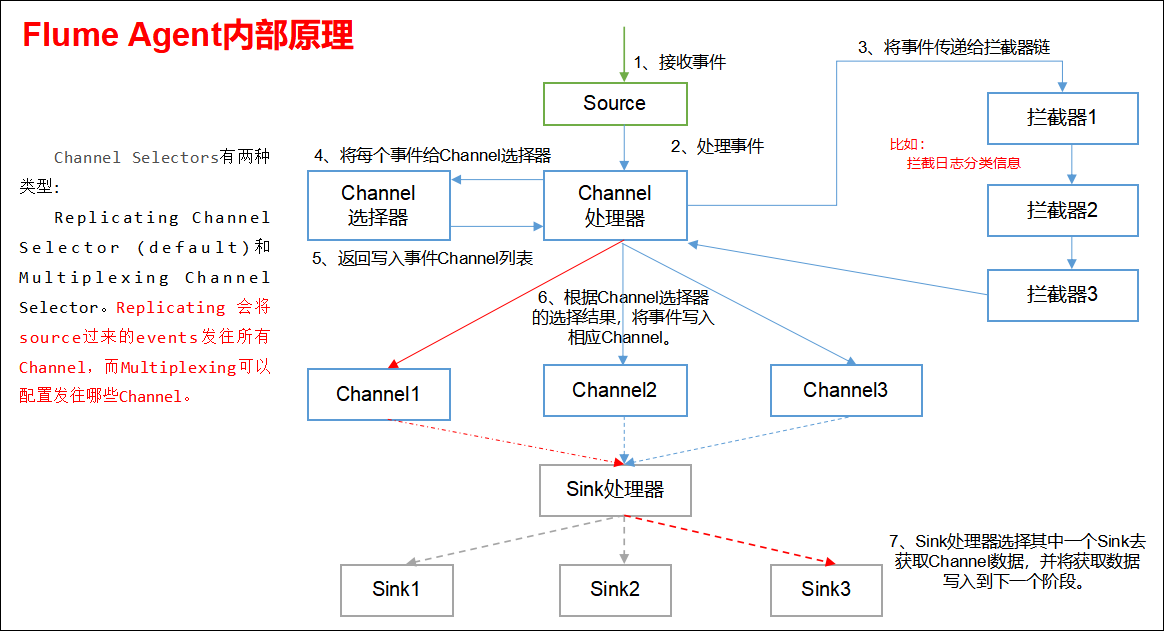
Apache Flume主要有以下几大模块组成:
- 数据源采集(Source)
- 数据拦截(Interceptor)
- 通道选择器(Channel Selector)
- 数据通道(Channel)
- Sink处理器(Sink Processor)
- Sink(Sink)
- 事件序列化(Serialization)
运行机制
Flume的核心是把数据从数据源(source)收集过来,再将收集到的数据送到指定的目的地(sink)。为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据。
Flume系统中核心的角色是agent。
在整个数据的传输的过程中,流动的是event,它是Flume内部数据传输的最基本单元。event将传输的数据进行封装。如果是文本文件,通常是一行记录,event也是事务的基本单位。event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
一个完整的event包括:event headers、event body、event信息,其中event信息就是flume收集到的日记记录。

Apache Nifi
一个易用、强大、可靠的数据处理与分发系统。基于Web图形界面,通过拖拽、连接、配置完成基于流程的编程,实现数据采集等功能。
NiFi是美国国家安全局开发并使用了8年的可视化数据集成产品,2014年NAS将其贡献给了Apache社区,2015年成为Apache顶级项目。
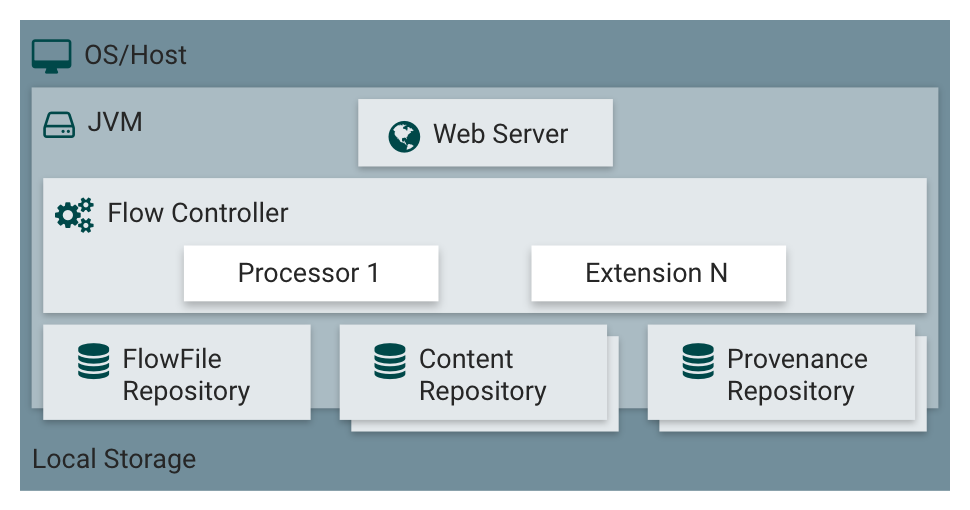
NiFi的核心概念
-
FlowFile
FlowFile表示在系统中移动的每个对象,FlowFile由两部分组成:
- content 内容 既数据本身
- attributes 属性 每条数据带上的属性信息.以键值对的形式.
- FlowFile Processor
- FlowFile处理器,由它完成对数据的实际处理工作.包括但不限于对数据内容和属性的加载,路由,转换,输出等.
- 处理器最灵活之处在于处理器可以读写FlowFile的属性信息,并且用自带的领域特定语言(DSL)对属性进行编程.
- Connection
- 由Connections把各个处理器链接起来,从而形成数据处理流程的有向无环图(DAG图).也称数据流, NiFi 中的 Flow.
- Connection 同时充当处理器间的队列,并且队列的属性高度可配置.
- 这些队列可以配置优先级,可以在设置阈值,可以实现反压。
- Flow Controller
- 流控制器对用户不可见的.它充当维护处理器如何连接和管理所有处理器所使用的线程及其分配的重要角色。
- Flow Controller充当促进处理器之间FlowFiles交换的代理。
- Process Group
- 为了方便管理,把一组特定的处理器及其连接组成的 Flow 放到一个处理组中去,可以通过输入端口接收数据并通过输出端口发送数据。
- 以这种方式,处理组可以通过组合其他组来创建全新组,形成更加复杂的DAG图( Flow 流)。
NiFi关键特性
- Flow 流高度可管理
-
保证交付
NiFi的一个核心理念是即使在非常高的规模下,保证交付也是必须的。这是通过有效使用专门的持久化的预写日志(WAL)和内容存储库来实现的。它们的设计可以实现非常高的事务处理速率,有效的负载分散,写入时复制以及发挥传统磁盘读/写的优势。
-
背压和数据缓冲机制
NiFi支持缓冲所有队列数据,以及在这些队列达到指定限制时提供背压的能力,或者在数据达到指定时间时使数据过期失效。
-
可配置优先级的队列
NiFi允许设置一个或多个优先级策略,用于如何从队列中检索数据。默认是先进先出,但有时候应该先拉取最新的数据,最大的数据或其他一些自定义方案。
-
Flow 流可配置特定的QoS(延迟v吞吐量,容量损失等)
在 Flow 流中有一些点是很关键的,且不能容忍丢失.或者有时候必须在几秒钟内处理和交付它。NiFi 可以对这些问题进行细粒度的特定配置。
-
- 易于使用
-
可视化的控制和命令
得益于强大的 web 操作界面.无论多么复杂的数据流都能在 web 界面上直观的呈现.整个数据处理流程,包括设计,控制,反馈和监控都可在web界面完成,一步到位.任何更改都能在界面上立马生效,完全不要部署的过程.对于整个数据流,更可以对中间某个处理器进行单独变更,实时生效.
-
数据流模板
对于设计好的数据流处理流,可以保存为模板来进行复用.模板可以导出成xml文件,导入到其他 NiFi 中进行多处使用.
-
数据溯源
flowfile 流过Flow 流时,NiFi会自动记录,索引并提供可用的起源数据,包括导入,导出,转换等。这些信息对于故障排除,优化等很有用处.
-
对历史数据进行细粒度的恢复
NiFi的内容存储库旨在充当历史记录的滚动缓冲区。数据仅在内容存储库过期时或存储空间不足时才会被删除。这与数据起源能力相结合,提供了非常精细的操作功能.包括对数据历史中的某一个点的点击查看内容,下载内容,处理回放等功能.所有数据都可以回溯到它生命周期中很早的某一点.
-
- 安全机制
-
系统内部安全
Flow 流中的流动的数据都可以进行加密传输
-
用户使用安全
支持用户认证和不同级别的用户授权(可读,管理数据流,系统管理)
-
多租户授权
-
- 可扩展的架构设计
-
可扩展组件
NiFi 的核心设计就是扩展. 它的 processors, Controller Services, Reporting Tasks, Prioritizers, and Customer User Interfaces 都是 可扩展的.
-
隔离的类加载器
自定义的类加载器保证了扩展的组件简单的依赖关系.
-
点到点的通信协议
NiFi实例之间的通信协议是NiFi 点到点(S2S)协议。S2S可以轻松,高效,安全地将数据从一个NiFi实例传输到另一个实例。NiFi 客户端 的 库也可以轻松在其他应用程序使用,以通过S2S来与NiFi 实例进行通信。S2S中支持基于套接字的协议和HTTP(S)协议作为底层传输协议,使得可以将代理服务器嵌入到S2S通信中。
-
- 灵活的扩容模型
-
更多的NiFi 实例
可以搭建 NiFi 集群,也可以不组成集群,多台机器使用 点到点 协议来协作.
-
更大的并发数量
直接修改处理器的并发数
-
NiFi架构

参考资料
Data Lake Services for Real-Time and Streaming Analytics
Deploying Kafka With the ELK Stack
Should I use Logstash or Elasticsearch ingest nodes?
Building an Open Data Platform: Logging with Fluentd and Elasticsearch