什么是数据湖?
数据湖是一个集中式存储库,允许您以任意规模存储所有结构化和非结构化数据。您可以按原样存储数据(无需先对数据进行结构化处理),并运行不同类型的分析 – 从控制面板和可视化到大数据处理、实时分析和机器学习,以指导做出更好的决策。
数据湖作为一种服务模型,是一种架构,是为了交付业务价值,而不仅仅是存储数据。
为什么需要数据湖?
通过数据成功创造商业价值的组织将胜过同行。Aberdeen的一项调查表明,实施数据湖的组织比同类公司在有机收入增长方面高出 9%。这些领导者能够进行新类型的分析,例如通过日志文件、来自点击流的数据、社交媒体以及存储在数据湖中的互联网连接设备等新来源的机器学习。这有助于他们通过吸引和留住客户、提高生产力、主动维护设备以及做出明智的决策来更快地识别和应对业务增长机会。
数据仓库与数据湖
区别
数据仓库是一个优化的数据库,用于分析来自事务系统和业务线应用程序的关系数据。事先定义数据结构和 Schema 以优化快速 SQL 查询,其中结果通常用于操作报告和分析。数据经过了清理、丰富和转换,因此可以充当用户可信任的“单一信息源”。
数据湖有所不同,因为它存储来自业务线应用程序的关系数据,以及来自移动应用程序、IoT 设备和社交媒体的非关系数据。捕获数据时,未定义数据结构或 Schema。这意味着您可以存储所有数据,而不需要精心设计也无需知道将来您可能需要哪些问题的答案。您可以对数据使用不同类型的分析(如 SQL 查询、大数据分析、全文搜索、实时分析和机器学习)来获得见解。
随着使用数据仓库的组织看到数据湖的优势,他们正在改进其仓库以包括数据湖,并启用各种查询功能、数据科学使用案例和用于发现新信息模型的高级功能。Gartner 将此演变称为“分析型数据管理解决方案”或“DMSA”。
| 特性 | 数据仓库 | 数据湖 |
|---|---|---|
| 数据来源 | 事务系统、运营数据库和业务线应用程序 | IoT设备、网站、移动应用程序、社交媒体和企业应用程序 |
| 数据格式 | 关系数据 | 非关系,半关系数据,关系数据 |
| Schema | 设计在数据仓库实施之前(写入型 Schema) | 写入在分析时(读取型 Schema) |
| 性价比 | 更快查询结果会带来较高存储成本 | 更快查询结果只需较低存储成本 |
| 数据质量 | 可作为重要事实依据的高度监管数据 | 任何可以或无法进行监管的数据(例如原始数据) |
| 用户 | 业务分析师 | 数据科学家、数据开发人员和业务分析师(使用监管数据) |
| 分析 | 批处理报告、BI 和可视化 | 机器学习、预测分析、数据发现和分析 |
数据湖与数据仓库可以共存
在数据湖体系结构中,计算资源分离是一种核心的抽象,这是Redshift Spectrum、Spark、Presto和Athena解决方案存在的原因。以Amazon的Athena为例,Athena不是一个数据仓库软件,而是一个基于开源FaceBook Presto开发的按需查询引擎,它将按需提供“计算”资源查询数据作为一项服务来提供。Amazon的Redshift Spectrum和Athena一样可以查询数据湖中的数据,利用的是从一个Redshift集群中分离出来的计算资源。
根据设计,数据湖中的查询数据服务可以很好地抽象出这个引擎模型,而且无论你在Google云上是否有亚马逊数据湖(AWS数据湖)、Oracle数据湖、Azure数据湖或BigQuery数据湖,模型都是类似的。可以通过Athena这类的查询引擎或者像Redshift、 BigQuery、Snowflake等“仓库”来查询数据湖数据内容,这些服务提供计算资源,而不是提供一个数据湖。
数据仓库不是数据湖
不能用数据仓库当数据湖使用。 两者使用场景不一样。数据湖的应用应用场景更广泛。
举个例子:仓库存储来自特定来源的计划好的货物,而湖泊来自河流、溪流和其他来源。
如果你非要用数据仓库替代数据湖, 数据仓库更像ODS,而且为了使数据仓库可以像数据湖一样使用,你要多背负很多技术债。 得不偿失。
数据湖不仅仅只存储数据(可以被当做ODS)
数据湖不仅仅可以存储数据,还可以兼容数仓、数据分析技术栈中的技术。事实上,大多数数据湖是动态的生态系统,而不是静态的封闭系统。当数仓负载适中时,数据湖是一个活跃数据源,源源不断为其输送数据,反之亦然,负载过重时,数据湖进行对数据进行适当地动态处理,以降低成本和提高效率。
数据湖对数据进行适当地组织,以便将下游价值传递给使用数据的下游系统,包括数仓。例如,数据湖在支持数仓整合事务数据方面发挥了积极的作用。
数据湖不仅仅只存储原始数据
根据设计,数据湖应该有一定程度的数据输入管理(即管理什么数据要进入数据湖)。如果你没有管理数据进入模式的意识,那么你其它地方的技术栈可能存在问题,这对于数仓或任何其它数据系统也是一样的,垃圾进,垃圾出。
数据湖的最佳实践应该包括一个配备初始数据池的模型,在这个初始数据池里,你可以最低限度地优化模型,以为下游处理数据或辅助处理数据。数据处理可能发生在Tableau或PowerBi之类的分析工具中,也有可能发生在加载数据到数仓(如Snowflake、Redshift和BigQuery)的应用程序中。
数据湖不仅仅适用于“大”数据
所有数据湖类型都应该采用一种抽象,以最大限度地降低风险,并提供更大的灵活性。此外,它们的结构应该便于数据处理,独立于数据规模的大小。当数据科学家、业务用户或者python代码使用数据湖时,确保它们拥有一个易于处理数据和可自定义数据规模的数据环境。
无论你的使用场景是机器学习、数据可视化、生成报告还是为数仓和数据集市输送数据,数据规模的不同,思考方式不同,有可能创造出使用这些数据湖的新方式。
数据湖和分析解决方案的基本要素
组织构建数据湖和分析平台时,他们需要考虑许多关键功能,包括:
- 数据移动
- 数据湖允许您导入任何数量的实时获得的数据。您可以从多个来源收集数据,并以其原始形式将其移入到数据湖中。此过程允许您扩展到任何规模的数据,同时节省定义数据结构、Schema 和转换的时间。
- 安全地存储和编目数据
- 数据湖允许您存储关系数据(例如,来自业务线应用程序的运营数据库和数据)和非关系数据(例如,来自移动应用程序、IoT 设备和社交媒体的运营数据库和数据)。它们还使您能够通过对数据进行爬网、编目和建立索引来了解湖中的数据。最后,必须保护数据以确保您的数据资产受到保护。
- 分析
- 数据湖允许组织中的各种角色(如数据科学家、数据开发人员和业务分析师)通过各自选择的分析工具和框架来访问数据。这包括 Apache Hadoop、Presto 和 Apache Spark 等开源框架,以及数据仓库和商业智能供应商提供的商业产品。数据湖允许您运行分析,而无需将数据移至单独的分析系统。
- 机器学习
- 数据湖将允许组织生成不同类型的见解,包括报告历史数据以及进行机器学习(构建模型以预测可能的结果),并建议一系列规定的行动以实现最佳结果。
数据湖的价值
能够在更短的时间内从更多来源利用更多数据,并使用户能够以不同方式协同处理和分析数据,从而做出更好、更快的决策。数据湖具有增值价值的示例包括:
- 改善客户互动
- 数据湖可以将来自 CRM 平台的客户数据与社交媒体分析相结合,有一个包括购买历史记录和事故单的营销平台,使企业能够了解最有利可图的客户群、客户流失的原因以及将提升忠诚度的促销活动或奖励。
- 改善研发创新选择
- 数据湖可以帮助您的研发团队测试其假设,改进假设并评估结果 – 例如在产品设计中选择正确的材料从而提高性能,进行基因组研究从而获得更有效的药物,或者了解客户为不同属性付费的意愿。
- 提高运营效率
- 物联网 (IoT) 引入了更多方式来收集有关制造等流程的数据,包括来自互联网连接设备的实时数据。使用数据湖,可以轻松地存储,并对机器生成的 IoT 数据进行分析,以发现降低运营成本和提高质量的方法
数据湖的挑战
数据湖架构的主要挑战是存储原始数据而不监督内容。对于使数据可用的数据湖,它需要有定义的机制来编目和保护数据。没有这些元素,就无法找到或信任数据,从而导致出现“数据沼泽”。 满足更广泛受众的需求需要数据湖具有管理、语义一致性和访问控制。
数据湖技术实现
数据湖架构
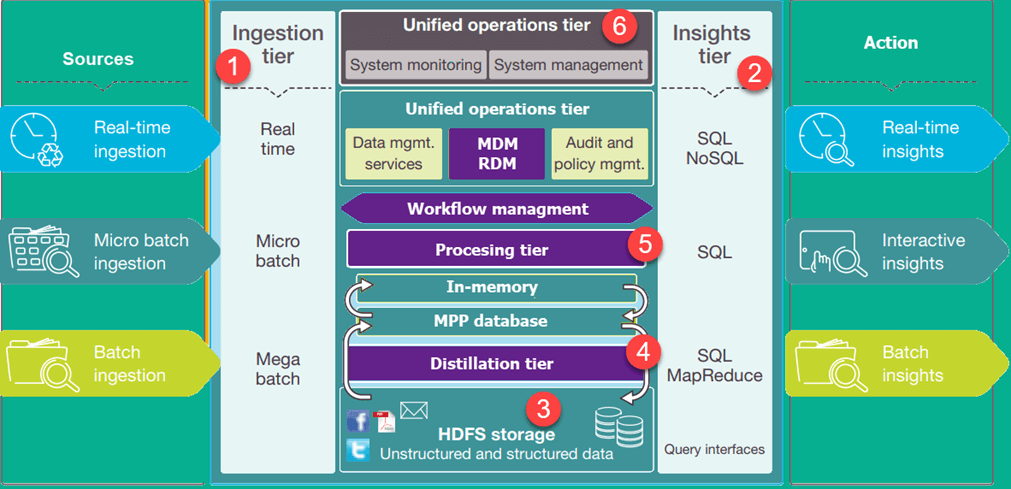
- Ingestion Tier: 数据收集层,可以批量或实时的收集数据到数据湖
- Insights Tier: 查询分析层
- HDFS:hfds不是必须的,但是它目前是最佳实现。
- Distillation tier:蒸馏层,从hdfs获取数据并进行结构化处理,可用于简单分析
- Processing tier:加工处理层, 可以批量的生成结构化数据,可以实时的进行数据分析和用户查询
- Unified operations tier:统一操作层,可以进行系统管理,系统监控,包括审计,流程管理等。
数据湖技术架构
云原生(aws)
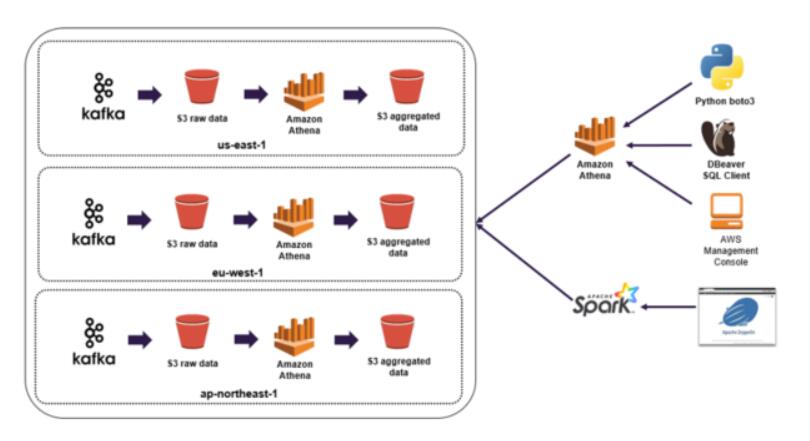
非云原生
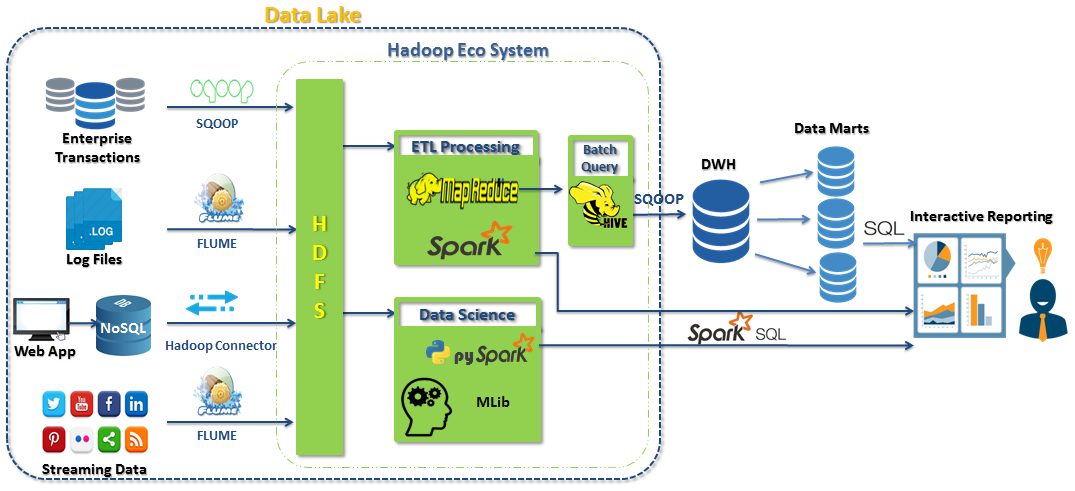
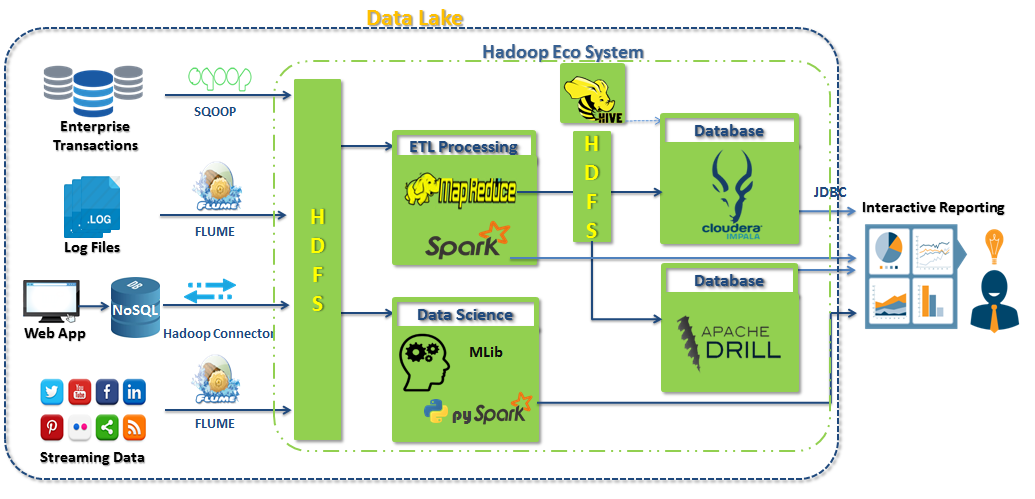
不同
- Apache Impala
- cloudera计划开发一个全新的SQL引擎Apache Impala(这是第一个最快的Hadoop开源MPP SQL引擎),Impala融入了几十年来关系型数据库研究的经验教训和优势。Impala使用完全开放的形式融入Hadoop生态,允许用户使用SQL操作Hadoop中的海量数据,目前已经支持更多存储选择,比如:Apache Kudu、Amazon S3、Microsoft ADLS、本地存储等。
- Apache Drill
- Apache Drill是一个开源的,对于Hadoop和NoSQL低延迟的SQL查询引擎。
数据湖存储
- 云存储(每个云服务都有类似的云存储,例如:aws s3)
- hdfs
数据湖存储层
Delta Lake
Delta Lake 是一个存储层,为 Apache Spark 和大数据 workloads 提供 ACID 事务能力,其通过写和快照隔离之间的乐观并发控制(optimistic concurrency control),在写入数据期间提供一致性的读取,从而为构建在 HDFS 和云存储上的数据湖(data lakes)带来可靠性。Delta Lake 还提供内置数据版本控制,以便轻松回滚。
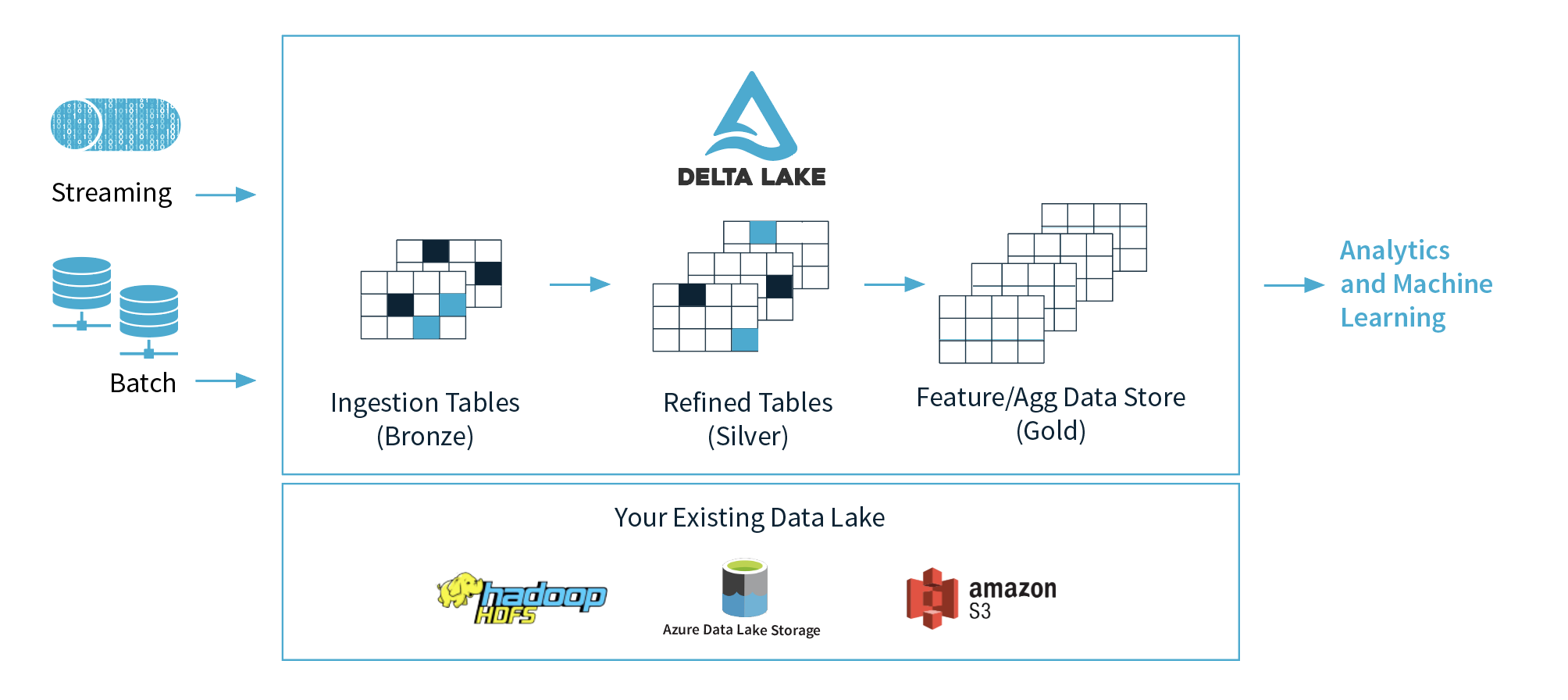
数据湖分析
- Presto
- Apache Spark
- Hive
参考资料
MongoDB 推出 Atlas Data Lake 预览版本
What is Data Lake? It’s Architecture
Data Lake Services for Real-Time and Streaming Analytics
How Our Threat Analytics Multi-Region Data Lake on AWS Stores More, Slashes Costs
Beyond Datawarehouse – The Data Lake
AWS re:Invent 2018: Big Data Analytics Architectural Patterns & Best Practices (ANT201-R1)